
GitHub Copilotを活用していると、「GPT5.3-CodexやCloudOpus4.6などの高性能モデルを使いたいのに、プレミアムリクエストの上限に達してしまった」という経験はないでしょうか。
日常的なコーディングからPull Request(PR)のレビューまで、AIのサポートは開発に不可欠になりつつあります。しかし、便利だからと無意識に重い処理を繰り返していると、いざという時に強力なモデルが制限されてしまい、作業効率が落ちてしまうことも少なくありません。
この記事では、プレミアムリクエストが消費される具体的な条件を整理し、無意識に上限を圧迫しがちな「PRレビュー」での注意点について解説します。さらに、GitHub CLI(ghコマンド)を活用して、リクエスト数を賢く節約しながら複数モデルでレビューを行う実践的なテクニックもご紹介します。
リクエスト上限に悩まされることなく、快適で効率的なAI開発環境を維持するためのヒントになれば幸いです。
なぜプレミアムリクエストが枯渇するのか?
GitHub Copilotでは、より高度な推論能力を持つモデル(GPT5.4やClaudeOpus4.6など)を利用する際、標準モデルとは異なる「プレミアムリクエスト」の枠が消費されます。まずは、どのような操作がこの上限を圧迫するのか、事実に基づいて確認しておきましょう。
プレミアムリクエストが消費される具体的なケース
高度なモデルを選択している状態で、主に以下のような操作を行った際にリクエストが大きく消費されます。
- 広範囲のコードベースを参照する質問(@workspaceの多用)
プロジェクト全体をスキャンして回答を生成するため、読み込むコンテキスト量(トークン数)が膨大になります。 - 複雑なインラインチャット(Cmd+I / Ctrl+I)での大規模リファクタリング
数十〜数百行に及ぶコードの書き換えや、ファイル全体を対象とした最適化指示は、重い処理としてカウントされやすい傾向があります。 - ターミナルエラーの自動解決
エラーログと関連ファイルの両方をAIに解析させる処理も、推論コストが高くなります。 - PR(Pull Request)の要約や自動レビューの生成
変更差分(Diff)全体を読み込ませて文章を生成するため、1回あたりの消費量が非常に大きくなります。
| 機能・操作 | 消費の重さ(目安) | 主な原因 |
| 通常のコード補完(Ghost Text) | 低 | 軽量なバックグラウンドモデルで処理されるため |
| チャットでの単純な質問 | 中 | 会話履歴の長さによって変動 |
@workspace を用いた検索 | 高 | プロジェクト全体のインデックスを参照するため |
| 広範囲のPRレビュー生成 | 極めて高 | 大量のコード差分を一度に解析するため |
【要注意】PRレビューの再実行連打は避けるべき

上記の表でも触れましたが、日々の開発において最もプレミアムリクエストを無駄に消費しやすいのが「PRレビュー機能」です。
PRの要約やレビューを生成する際、AIは変更前後のファイル差分をすべてコンテキストとして読み込みます。これは非常に重い処理です。
ここで初心者が陥りやすいのが、「生成されたレビュー内容が少し気に入らないから」という理由で、再生成ボタン(Regenerate)を何度も連打してしまうことです。
少し出力のニュアンスを変えたいだけであっても、再実行するたびに巨大な差分データの読み込みと高度な推論が最初から行われ、貴重なリクエスト枠がゴリゴリと削られていきます。結果として、「いざ複雑なアルゴリズムの相談をしたい時に上限に達している」という事態を引き起こします。
リクエストを無駄にしないための基本テクニック
PRレビューの罠を避けるだけでなく、日常的なコーディングでも以下のポイントを意識することで、リクエストの消費を大きく抑えることができます。
1. タスクに応じたモデルの使い分け
すべての作業をGPT5.4やCloudOpus4.6などの最新モデルで行う必要はありません。
- 標準モデル(GPT5-mini等)が適している作業:単純なボイラープレートの生成、ドキュメントのフォーマット整形、変数のリネーム、基本的なメソッドの作成。
- 高度なモデル(GPT-4o, Claude 4.6 Sonnet等)に頼るべき作業:複雑なビジネスロジックの設計、原因不明のバグ調査、パフォーマンスの最適化を伴うリファクタリング。
普段は標準モデルを選択しておき、難易度の高いタスクに直面した時だけモデルを切り替えるのが、最も堅実な節約術です。
モデルの使い分けやAgent Modeの活用については、以下の記事でも詳しく解説しています。
[完全版] GitHub Copilot活用術!導入からAgent Mode/最新モデル使い分けまで徹底解説

2. 参照コンテキスト(ファイル)を最小限に絞る
チャットに質問を投げる際、AIに読ませるファイルを必要最小限にコントロールすることが重要です。
@workspace は便利ですが、常に使うのはリクエストの無駄遣いです。「#file」やエディタの選択範囲機能を使って、対象となる数行〜数十行のコードだけを明示的にコンテキストに含めるように習慣づけましょう。読み込ませる情報が少ないほど、推論にかかるリクエスト消費も抑えられ、回答の精度もかえって向上することが多いです。
また、毎回同じような前提条件を指示する手間を省きたい場合は、Custom Instructionsを活用してAIの振る舞いを固定化しておくのも有効な手段です。
【脱・毎回指示】GitHub Copilot Custom Instructionsで自分専用のAIアシスタントを育てる設定手順

【実践】GitHub CLIを活用したPRレビュー手法
ブラウザ上のGitHub UIやエディタの拡張機能からPRレビューを依頼すると、裏側では自動的に最も強力(=リクエスト消費が激しい)モデルが選択され、プロジェクト全体のコンテキストが読み込まれることが少なくありません。
そこで、GitHub CLI(ghコマンド)を活用し、自分の手元で意図的にモデルを使い分けながらレビューを行う方法をご紹介します。
ブラウザのUIに頼らずGitHub CLI (gh) を使うメリット
CLIを使ってターミナル上で差分(Diff)を取得し、それをAIに渡すアプローチには、リクエスト節約の観点で以下の大きなメリットがあります。
- 取得する差分データを自分でコントロールできる
無関係な自動生成ファイル(package-lock.jsonなど)の差分を除外してからAIに渡すことができるため、トークン消費を大幅に削減できます。 - 目的別に複数のモデルを使い分けられる
「単純なタイポやコーディング規約のチェックは軽量モデルで」「複雑なロジックの脆弱性チェックは強力なモデルで」といった使い分けが、手元で簡単に実行可能です。
以下は、CLIを用いたレビュー手順の全体像です。
| ステップ | アクション | 使用するモデルの例 | 目的 |
| 1. 差分取得 | gh pr diff でコード差分を取得 | (なし) | レビュー対象のテキスト化 |
| 2. 一次レビュー | 取得した差分をAIに渡す | GPT-4o-mini 等 | 構文エラーや命名規則の確認 |
| 3. 二次レビュー | 懸念箇所を絞って深掘り | GPT-4o / Claude 3.5 等 | ロジックの欠陥や計算量の最適化 |
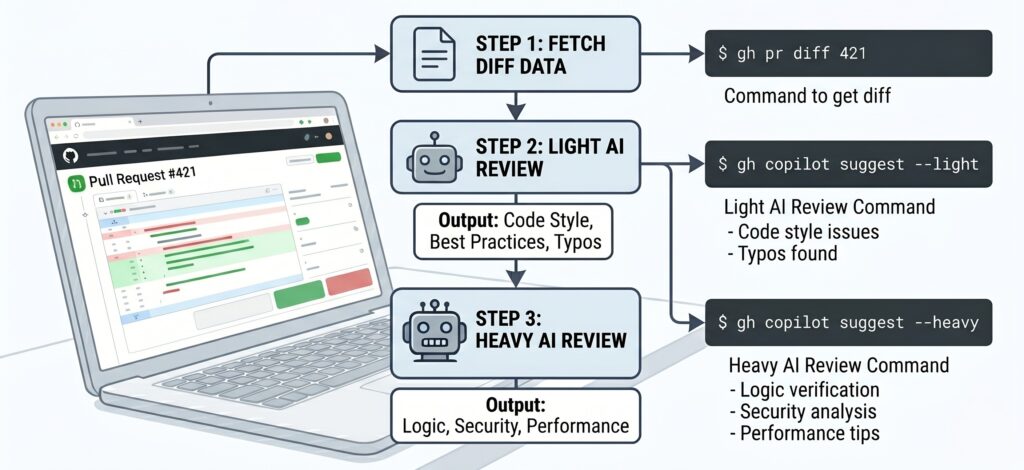
複数モデルを活用してレビューを行うプロンプト例
実際にターミナル環境でPRのレビューを行うための具体的なコマンドとプロンプトの例を紹介します。
まずは、GitHub CLIを使って該当PRの差分(Diff)テキストとして抽出します。
# PR番号123の差分を取得し、不要なファイル(例:lockファイル)を除外して保存
gh pr diff 123 | grep -v "package-lock.json" > pr_diff.txt次に、この pr_diff.txt の内容をベースに、段階的にAIへレビューを依頼します。
ターミナル上で動くAIツール(gh copilot や、その他のCLI向けLLMツール)を使用する想定のプロンプトです。
【STEP1】軽量モデル(GPT5-miniなど)へのプロンプト例:一次チェック
以下のコード差分(Diff)をレビューしてください。
主に「明らかな構文エラー」「タイポ」「一般的なコーディング規約からの逸脱」に絞って指摘をお願いします。
複雑なロジックの評価は不要です。簡潔に箇条書きで出力してください。
[ここに pr_diff.txt の内容をペースト、またはパイプで渡す]【STEP2】強力なモデル(GPT5.4 / Claude 4.6 Sonnetなど)へのプロンプト例:深掘り
(STEP1で抽出された特定の関数や、ロジックが複雑な部分だけを抜粋して)
以下の変更箇所について、シニアエンジニアの視点で詳細なレビューをお願いします。複雑なロジックの評価は不要です。簡潔に箇条書きで出力してください。
- パフォーマンス上の懸念(N+1問題やメモリリークなど)はないか
- エラーハンドリングは適切に実装されているか
- よりシンプルに書ける代替案があればコード例とともに提示してほしいこのように、「全体を軽く舐める処理」と「局所を深く考察する処理」を意図的に分割することで、再実行の連打を防ぎ、プレミアムリクエストの消費を最小限に抑えつつ、質の高いレビュー結果を得ることができます。
GitHub CLI自体の基本的な使い方やセットアップについては、以下の記事も参考にしてみてください。
GitHub Copilot CLIの使い方と活用例を徹底解説!ターミナル作業をAIで効率化

プロの視点:AIツールとの上手な向き合い方(コラム)
ここまでリクエストの節約術を解説してきましたが、最後に少しだけエンジニアとしての視点をお伝えします。
CopilotなどのAIツールは魔法ではなく、あくまで私たちの思考を拡張してくれる「優秀なアシスタント」です。プレミアムリクエストの上限を気にするあまり、AIへの指示(プロンプト)を考えることに疲弊してしまっては本末転倒です。
上限に達してしまった時は、「自分でコードを読み解き、ドキュメントに当たる良い機会」と捉えるのも一つの手です。AIが提示したレビューを鵜呑みにせず、自分で差分を追いかける時間を持つことで、長期的なエンジニアリングスキルの向上に繋がります。「AIに任せる部分」と「自分の頭で考える部分」のバランスをうまくとることが、現代の開発者にとって最も重要なスキルだと言えるでしょう。
まとめと次のステップ
本記事では、GitHub Copilotのプレミアムリクエスト上限に悩む方に向けて、以下のポイントを解説しました。
- 重い処理を知る:
@workspaceの多用や、広範囲のPRレビューはリクエスト消費が激しい。 - NG行動を避ける: レビュー結果が気に入らないからといって、再生成(Regenerate)を連打しない。
- CLIを活用する: GitHub CLI(
gh pr diff)を使って差分を抽出し、軽量モデルと強力なモデルを段階的に使い分ける。
これらの小さな工夫を毎日の開発に取り入れるだけで、本当に必要な時に強力なAIのサポートをフル活用できるようになります。
まずは次回のPRレビューから、ブラウザのボタンを安易に押す前に、CLIで差分を確認する癖をつけてみてはいかがでしょうか。
次におすすめの記事
開発効率をさらに高めたい方は、ターミナル作業そのものをAIで自動化するアプローチもぜひ試してみてください。
GitHub Copilot CLIの最新活用事例!次世代コマンドで開発を自動化しよう



コメント