
最近、GitHub上で非常に巧妙なコードの難読化手法が発見され、エンジニアの間で話題になっています。一見すると短い1行のコードの中に、実は何万文字もの「見えないデータ」が隠されており、それを実行させるというものです。
このような悪用手法を理解し、適切に防御するためには、私たちが普段何気なく使っている「UTF-8」という文字コードの仕組みを正しく知っておく必要があります。
この記事では、UTF-8の基本的な仕組みから、見えないUnicode文字を利用した最新の攻撃手法(EtherHidingなど)、そして開発現場で身を守るための実践的な対策までを分かりやすく解説します。
文字コードへの理解を深め、より安全で堅牢なコードを書けるエンジニアを目指しましょう。
UTF-8とは?エンジニアが知っておくべき基本の仕組み
プログラミングやWeb開発において、UTF-8は現在のデファクトスタンダード(事実上の標準)です。しかし、「なんとなく設定している」という方も多いのではないでしょうか。まずはその基本構造を整理します。
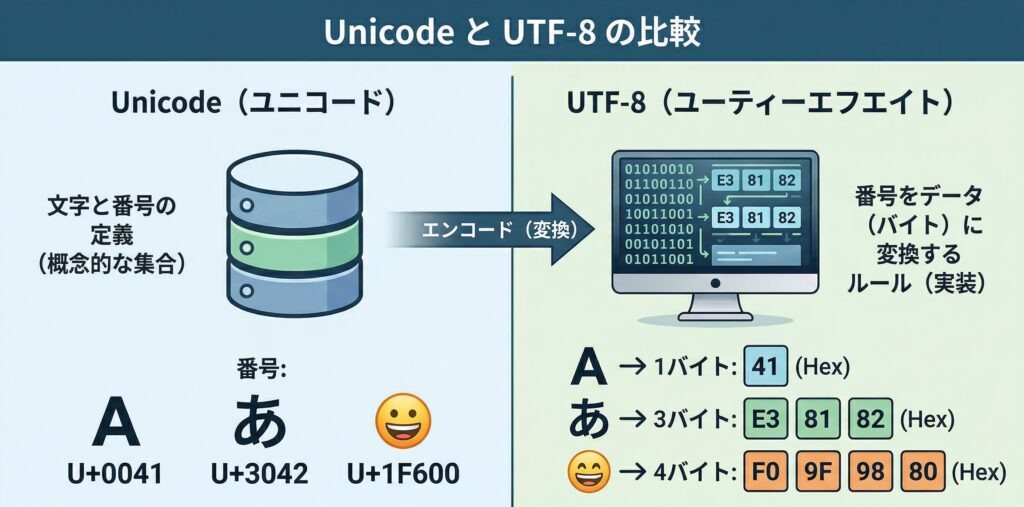
Unicode(文字セット)とUTF-8(エンコード方式)の違い
文字コードを理解する際、初心者がつまずきやすいのが「Unicode」と「UTF-8」の混同です。この2つは役割が明確に異なります。
| 名称 | 役割 | 例え話 |
| Unicode | 世界中の文字を集めた「文字の背番号表」(文字セット) | 「『あ』は123番、『A』は45番」というルールブック |
| UTF-8 | 背番号をPCが理解できる「0と1のデータ」に変換する方式(エンコーディング) | ルールブックの番号をPC用に翻訳・圧縮する仕組み |
つまり、Unicodeという共通の辞書があり、その辞書を効率よくデータとして保存・通信するための具体的な翻訳ルールの一つがUTF-8です。
可変長エンコーディングの強みとは?
UTF-8の最大の特徴は「可変長エンコーディング」を採用している点です。
- 半角英数字(ASCII文字): 1バイトで表現(データ容量が軽い)
- 日本語などの複雑な文字: 3〜4バイトで表現
もしすべての文字を同じサイズ(例:常に4バイト)で保存しようとすると、英語だけのファイルは無駄にファイルサイズが大きくなってしまいます。UTF-8は文字に合わせてデータサイズを柔軟に変えることができるため、容量を節約しつつ世界中の言語を扱えるという強力なメリットを持っています。
【事例解説】「見えないUnicode」を使った悪用手法
UTF-8とUnicodeは非常に便利ですが、世界中のあらゆる文字(記号や制御文字を含む)を定義しているため、それを逆手に取った悪用手法も存在します。
話題の「EtherHiding」と見えないデータの正体
最近確認された「EtherHiding」と呼ばれる手口などでは、開発者が目視で確認できない「ゼロ幅文字(Zero-Width Characters)」などの特殊なUnicode文字が悪用されています。
ゼロ幅文字とは、その名の通り「画面上には表示されないが、データとしては存在している文字」のことです。元々はアラビア語などの複雑な文字のレンダリングを制御するために用意されたものですが、攻撃者はここに悪意のあるコードを隠します。
添付画像のコードはどのように実行されているのか?
GitHubの多数のリポジトリで展開された不正なコードの挿入事例を見てみましょう。一見すると、次のような無害で短いコードに見えます。
s(``)
しかし、このバッククォート( )の間に、数万桁にも及ぶ「見えないUnicodeデータ」が格納されています。
プログラムがこの文字列を読み込むと、見えないデータを可視化されたコード(実行可能なスクリプト)に変換し、外部(Solanaの特定アドレスなど)へアクセスして追加のマルウェアを取得・実行してしまうのです。
ゼロ幅文字(Zero-Width Characters)などのトリック
攻撃者はなぜこのような手法を使うのでしょうか。最大の理由は「人間の目と、一般的なセキュリティスキャンの両方を欺くため」です。
コードレビュー担当者がソースコードを見ても、ただの空の文字列にしか見えません。しかし、コンピュータはそこにある見えないバイトデータを正確に読み取ってしまいます。これがUTF-8の懐の深さを悪用した、非常に斬新で厄介な手口です。
UTF-8の便利な使い方と開発時の注意点
セキュリティのリスクを理解した上で、日常の開発においてUTF-8を正しく扱うためのポイントを確認しておきましょう。
絵文字や多言語対応におけるグローバルスタンダード
現代のWebアプリケーションでは、多言語対応だけでなく「絵文字(Emoji)」の処理が必須です。絵文字もUnicodeで定義されており、UTF-8でエンコードされます(多くは4バイト)。
データベース(例えばMySQLの utf8mb4 など)やファイルの保存形式をUTF-8に統一しておくことで、環境ごとの文字化けやシステムエラーを未然に防ぐことができます。
文字化けを防ぐためのBOM(Byte Order Mark)の扱い方
UTF-8を扱う際によく目にするのが「BOM付き」と「BOM無し」です。
BOMとは、ファイルの先頭につける「このファイルはUTF-8で書かれていますよ」という目印のデータです。
- 基本ルール: プログラミングのソースコードやWebファイル(HTML, PHPなど)を作成する際は、原則として「UTF-8(BOM無し)」を使用します。
- 理由: BOMが付いていると、コンパイラやサーバーが予期せぬエラーを起こしたり、画面の先頭に謎の空白が表示されたりする原因になるためです。
見えない脅威からシステムを守るには?
「見えない文字」による攻撃からプロジェクトを守るためには、人間の目だけに頼らない仕組みづくりが必要です。
コードレビュー時に気をつけるべきポイント
GitHubなどのPR(プルリクエスト)をレビューする際、不自然にファイルサイズが大きい変更や、意味のない変数の宣言には注意が必要です。また、CI/CDパイプラインに、不正な文字コードや難読化されたパターンを検知する静的解析ツール(Linterなど)を組み込むことが推奨されます。
エディタ(VSCode等)の可視化設定を活用する
最も簡単で効果的な対策は、開発エディタの設定を変更し、見えない文字を「見える」ようにすることです。
例えば、エンジニアに人気のVSCodeでは、設定(settings.json)で以下のように記述することで、制御文字や空白文字をハイライトさせることができます。
”editor.renderControlCharacters”: true (制御文字を表示する)
”editor.renderWhitespace”: “all” (空白文字を明示的に表示する)これにより、ソースコード内に不審な見えないデータが混入していても、エディタ上で視覚的に気づくことが可能になります。
VSCodeを活用した開発効率化やその他の便利な設定については、以下の記事でも詳しく解説していますので、ぜひ参考にしてみてください。
【エンジニア必見】VSCodeショートカットキー最強一覧!極意と設定マニュアル
まとめ:文字コードの深い理解がエンジニアの武器になる
今回はUTF-8の基本から、「見えないUnicode」を利用した最新の悪用事例までを解説しました。
- UTF-8は可変長で世界中の文字を扱える強力なエンコーディング方式。
- 攻撃者は「画面に表示されない文字」を悪用して、ソースコードに不正なスクリプトを隠蔽する(EtherHidingなど)。
- 対策として、エディタの可視化設定やツールの活用が必須。
「文字コード」は地味なテーマに思われがちですが、システムの根幹を支える重要な知識です。今回のような最新の手口を知ることで、なぜ適切なエンコーディングやエディタの設定が必要なのかが、より深く理解できたのではないでしょうか。
まずは今日、ご自身のVSCodeなどのエディタ設定を見直し、制御文字が適切に表示されるようになっているか確認してみてください。


コメント