
「GPT-5シリーズの登場でAIの性能が飛躍したと聞くけれど、内部のアーキテクチャはどう変わったのだろう?」
「最新のGPT-5.4で追加された『Computer Use』や105万トークンの仕組みを、エンジニアとして正確に把握しておきたい」
AI技術の進化スピードは凄まじく、モデルごとの構造や強みを理解できていないと、開発現場での技術選定やプロンプトの最適化で遅れをとってしまいますよね。
この記事では、GPT-5から最新のGPT-5.4(Mini・Codex含む)までのアーキテクチャの全貌と進化の歴史を、プロのエンジニア視点で徹底解剖します。
この記事を読むメリット
- GPT-5シリーズの内部構造(推論と生成の統合)が図解で直感的にわかる
- 5.4の最新機能(Computer Use、Tool Search)の仕組みを理解できる
- APIコストの最適化や、自社開発への実践的な応用シナリオが身につく
AIアーキテクチャの深い理解は、より高度なアプリケーション開発への最短ルートです。ぜひ最後まで読み進めて、次世代AIのポテンシャルを最大限に引き出しましょう!
はじめに:GPT-5シリーズがもたらしたアーキテクチャの革新とは?
結論から言うと、GPT-5シリーズにおける最大の革新は「思考(推論)」と「出力(生成)」プロセスのシームレスな統合です。
従来のGPT-4までは、入力されたプロンプトに対して「確率的に最も自然な次の単語」を予測して出力する、いわば「超優秀なタイピスト」でした。前世代の構造については、【完全図解】GPT-4シリーズ(4/4o/4.1等)のアーキテクチャ構造と進化の歴史でも詳しく解説しています。
対してGPT-5シリーズは、内部で複雑な問題解決ルートを構築してから出力を行う「熟考する研究者」へとアーキテクチャが根本から再構築されています。これにより、ハルシネーション(幻覚)が劇的に減少し、より論理的で精度の高い回答が可能になりました。
GPT-5の基礎アーキテクチャ:推論と生成の「統合」
従来のメインラインと「oシリーズ(推論)」の融合
GPT-5の基盤となるのは、GPT-4の「Transformerアーキテクチャ」と、高度な推論能力に特化した「oシリーズ(o1/o3等)」の技術の統合です。
内部では、即次応答が求められるタスクには従来の軽量なパスを使い、複雑なコーディングや数学的証明には「Chain of Thought(思考の連鎖)」を内部で隠蔽して実行するハイブリッド構造が採用されています。
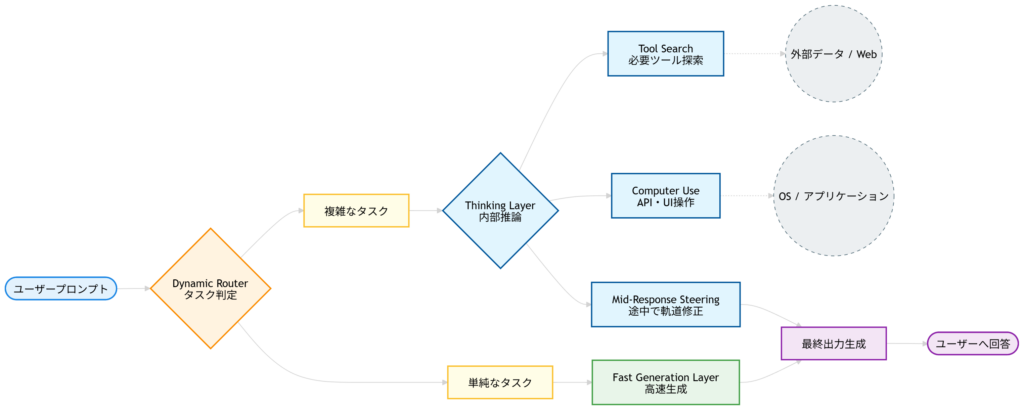
動的ルーティング機構による「選ばない」AI体験
ユーザーが「どのモデルを使うべきか」を意識する必要がなくなったのも大きな特徴です。
内部の動的ルーター(Dynamic Router)が、入力されたプロンプトの複雑さを瞬時に計算し、以下のように最適なサブモデルへ処理を振り分けます。
- 単純な挨拶や要約 → 軽量モデル(Mini相当)へルーティング
- 複雑なアルゴリズムの実装 → 推論特化モデルへルーティング
これにより、レスポンス速度の向上と計算コストの最適化が同時に実現されています。
モデルの派生と進化:5〜5.4までの系譜と特徴
GPT-5のリリース以降、用途に合わせてアーキテクチャの最適化が進みました。各モデルの特徴を比較表で整理します。
| モデル名 | 主な用途・強み | アーキテクチャの特徴 | コンテキストウィンドウ |
| GPT-5 | 汎用的な高度推論 | 推論/生成ハイブリッド基盤 | 128k ~ 256k |
| GPT-5.x Mini | エッジAI・高速処理 | 知識蒸留による徹底的な軽量化 | 128k |
| GPT-5.x Codex | 開発支援・コード生成 | GitHubリポジトリ連携、AST解析強化 | 256k |
| GPT-5.4 | 自律型エージェント | Computer Use、Tool Searchのネイティブ統合 | 105万 |
軽量・高速化の極み「GPT-5.x Mini」の構造
Miniシリーズは、巨大なGPT-5モデルから必要な知識だけを抽出する「知識蒸留(Knowledge Distillation)」技術が極限まで高められています。
スマートフォンなどのエッジデバイスでの動作や、リアルタイム性が求められるカスタマーサポートAIなどに最適なアーキテクチャです。
コーディング特化「GPT-5.x Codex」の進化
エンジニアにとって最も恩恵が大きいのがCodexの進化です。単なるテキスト予測ではなく、プログラムの抽象構文木(AST)を直接理解するアーキテクチャが組み込まれました。
これにより、リポジトリ全体の構造を把握した上でのリファクタリング提案が可能になっています。
開発環境への組み込みについては、【完全版】GitHub Copilot活用術!導入からAgent Mode/最新モデル使い分けまで徹底解説も併せて読むと、実践的な活用イメージが湧きやすいはずです。
【最新】GPT-5.4アーキテクチャのブレイクスルー
2026年の最新モデル「GPT-5.4」では、AIがシステムを直接操作するためのアーキテクチャがネイティブ実装されました。その内部フローを図解します。
105万トークンを支えるContext Window拡張技術
GPT-5.4では、コンテキストウィンドウが105万トークンという桁違いの領域に到達しました。
これを可能にしたのが、「Ring Attention」や「Sparse Attention」と呼ばれる、メモリ消費を抑えつつ長文の文脈を保持する新しいアテンション機構です。分厚い仕様書や数万行のソースコードを丸ごと読み込ませても、精度が落ちません。
外部操作を統合したネイティブ「Computer Use」
最大のブレイクスルーは、AIが仮想環境のブラウザやターミナルを直接操作する「Computer Use」のネイティブ統合です。
従来の「関数呼び出し(Function Calling)」とは異なり、モデル自体が画面のピクセル情報を認識し、マウスクリックやキーボード入力を自律的に生成するアーキテクチャを採用しています。
トークン消費を抑える「Tool Search(遅延読み込み)」
膨大なコンテキストを扱う際のコスト課題を解決したのがTool Searchです。
必要な外部データやドキュメントを最初から全てコンテキストに積むのではなく、推論の途中で「必要になったタイミングで動的に読み込む(遅延読み込み)」アーキテクチャにより、APIのトークン消費量を劇的に削減しています。
Mid-Response Steering(思考途中の軌道修正)の実装
人間が「あ、やっぱりこうしよう」と考え直すように、GPT-5.4は回答を生成している途中で矛盾に気づくと、内部状態をロールバックして別のアプローチを再計算する「Mid-Response Steering」機能を持っています。これが、驚異的な論理的正確さを担保しています。
💡GPT-5シリーズを開発に活かすには?
1. APIコスト最適化とモデルの使い分け
GPT-5.4は強力ですが、すべての処理を任せるとAPIコストが跳ね上がります。
システムの入り口にGPT-5.x Mini(またはGPT-4o mini)を配置してタスクを分類し、高度な推論が必要な処理(例:複雑な要件定義のパースや、バグの根本原因解析)のみGPT-5.4へルーティングする多段アーキテクチャの設計が今後の基本戦略になります。
2. 自律型エージェント開発への応用
Computer UseやTool Searchの登場により、「AIエージェント」の開発ハードルが大きく下がりました。
例えば、Python 3.15の新しい観測性ツールを活用してAIエージェントのログを監視したり、.NET 10とC# 14の新機能を使って、エンタープライズ向けの堅牢なバックエンドとGPT-5.4を連携させるなど、モダンな技術スタックとの組み合わせが非常に強力です。
まとめと次のステップ:GPT-5アーキテクチャの理解から実践へ
いかがでしたでしょうか。この記事では、GPT-5からGPT-5.4に至るアーキテクチャの進化について解説しました。
- 基礎アーキテクチャ:従来のテキスト生成に、oシリーズの「深い推論能力」が統合された。
- モデルの派生:エッジ向けのMini、開発特化のCodexなど、用途別の最適化が完了。
- 5.4のブレイクスルー:105万トークン、Computer Use、Tool Searchにより「自律操作」の領域へ。
GPTシリーズは、単なるチャットツールから「システムを制御する頭脳」へと完全にシフトしました。このアーキテクチャの特性を理解したエンジニアこそが、これからのAI開発をリードしていくはずです。
次にとるべきアクション
アーキテクチャの歴史をさらに深く理解したい方は、ぜひ以下の記事もあわせてご覧ください。過去の進化の文脈を知ることで、今後のAIトレンドを予測する力が身につきます!
👉 あわせて読みたい


コメント