
「GPT-4の回答精度が圧倒的に高いのはなぜ?」
「GPT-4oやGPT-4.1など、モデルが増えすぎて中身の違いがよく分からない…」
AIを活用した開発や業務効率化を進める中で、このような疑問を抱いたことはありませんか?
表面的なプロンプトのテクニックだけでなく、「AIが内部でどのように情報を処理しているのか(アーキテクチャ)」を理解することは、エンジニアやAIユーザーにとって大きな武器になります。
この記事では、現役ITエンジニアの視点から、GPT-4シリーズ(4、4 Turbo、4o、4.1、4.1 mini)のアーキテクチャの違いと進化の歴史を徹底解説します。
最後まで読むことで、各モデルの強みを活かした最適なモデル選択と、AIの構造に基づいた効果的なプロンプト作成ができるようになります。ぜひ実践に役立ててください。
はじめに:なぜ今、AIの「アーキテクチャ」を学ぶべきか?
ここ数年で生成AIの進化スピードは凄まじく、数ヶ月単位で新しいモデルが登場しています。しかし、そのすべてをブラックボックスとして扱うのは非常にもったいないことです。
アーキテクチャ(内部構造)を理解するメリットは以下の3点に集約されます。
- コストの最適化:タスクに対してオーバースペックなモデルを選ばなくなる。
- パフォーマンスの最大化:モデルの「得意・不得意」を構造レベルで理解できる。
- トラブルシューティング:ハルシネーション(嘘の出力)が起きやすい条件を予測できる。
次項からは、AIの歴史の大きな転換点となった「GPT-3からGPT-4への進化」について見ていきましょう。
GPT-3からGPT-4への劇的な進化:何が変わったのか?
GPT-3からGPT-4への進化は、単なる「パラメータ(脳のシナプスのようなもの)の増加」だけではありません。「計算の効率化」という構造的な大革命が起きました。
💡 あわせて読みたい
前世代であるGPT-3のアーキテクチャや、3.5・Turboへの進化の過程については、以下の記事で詳しく図解しています。基礎からしっかりおさらいしたい方は、ぜひ先にご覧ください。
劇的な効率化を生んだ「MoE(Mixture of Experts)」構造
従来のGPT-3は「Dense(密)モデル」と呼ばれ、1つの質問に答えるためにネットワーク全体のパラメータをフル稼働させていました。これは例えるなら、「簡単な足し算をするのにも、会社全社員(数千億人)を招集して会議をしている状態」です。
これに対し、GPT-4で採用されたと言われているのが「MoE(Mixture of Experts:専門家の混合)」というアーキテクチャです。
MoEでは、モデル内部に「数学の専門家」「翻訳の専門家」「コード生成の専門家」など、複数の小さなエキスパートモデルが並行して存在します。質問が入力されると、「ルーター」と呼ばれる振り分け役が、その質問に最適な専門家(通常は2つ程度)だけを選んで回答させます。
【図解】DenseモデルとMoEの違い
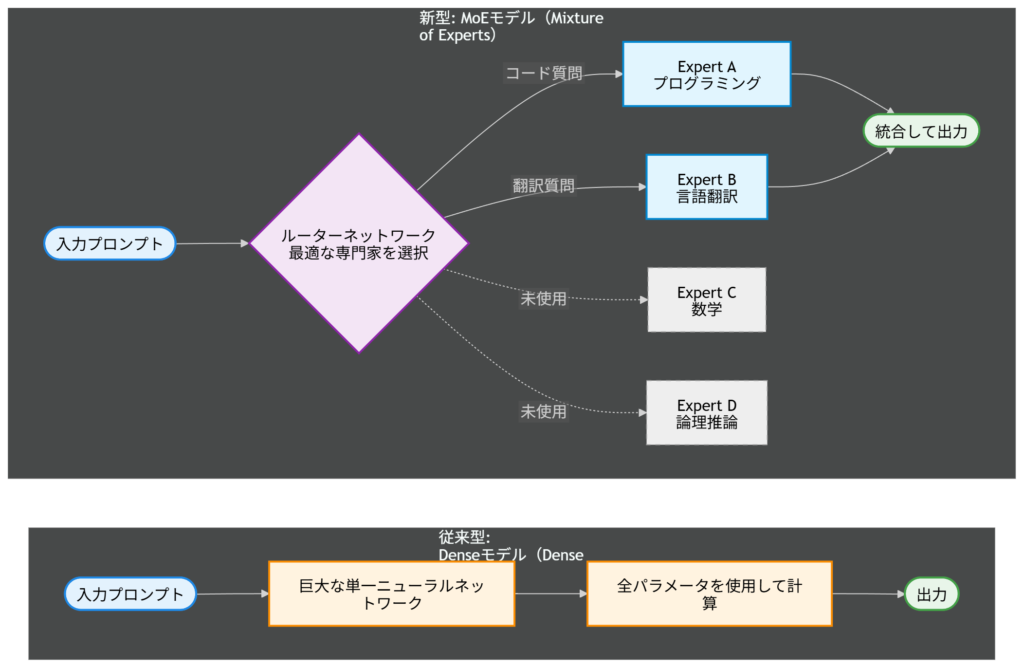
このMoEアーキテクチャにより、GPT-4は巨大な知識を持ちながらも、計算コスト(消費電力や処理時間)を抑えて高速に回答することが可能になったのです。
GPT-4シリーズ各モデルのアーキテクチャ比較
ここからは、GPT-4以降に登場した各モデルのアーキテクチャの特徴を比較してみましょう。
| モデル名 | アーキテクチャの主な特徴と進化のポイント | コンテキスト長 | 得意な領域・用途 |
| GPT-4 | MoE構造の本格採用。圧倒的な推論能力を持つが、処理速度は比較的遅め。 | 8K / 32K | 複雑な論理構築、高度な文章生成 |
| GPT-4 Turbo | GPT-4のアーキテクチャを軽量化・最適化し、処理速度とコストを改善。 | 128K | 長文ドキュメントの読み込み、実務全般 |
| GPT-4o (Omni) | 真のマルチモーダル・ネイティブ。 テキスト・音声・視覚を単一のニューラルネットワークで統合処理し、超低遅延を実現。 | 128K | リアルタイム音声対話、画像解析、総合タスク |
| GPT-4.1 | より自律的なエージェント機能に特化。複数ステップの推論や外部ツールの連携精度がアーキテクチャレベルで向上。 | 100万〜 | 高度なコーディング支援、自律型リサーチ |
| GPT-4.1 mini | 4.1のアーキテクチャをベースにした超軽量・高速モデル。ルーチンタスクにおけるコストパフォーマンスが最高。 | 128K〜 | 日常的なチャット、簡単なデータ処理 |
特にGPT-4o(Omni)の登場は大きなブレイクスルーでした。従来は「音声をテキストに変換」→「AIが思考」→「テキストを音声に変換」という3つの独立したモデル(アーキテクチャ)を繋いでいましたが、GPT-4oはこれらを1つのモデルで同時に処理できるようになったため、人間のようなリアルタイムな会話が可能になっています。
アーキテクチャを支える重要技術(エンジニア向け)
AI開発のスキルアップを目指す方向けに、最新アーキテクチャを支えるコア技術を2つピックアップします。
1. Attention機構とコンテキストウィンドウの拡張技術
GPTの心臓部であるTransformerアーキテクチャにおける「Attention(注意機構)」は、入力された文章の「どの単語に注目すべきか」を計算します。
最新のモデルでは、計算量を抑えながらより長い文章(100万トークンなど)を記憶できるよう、Ring AttentionやSparse Attentionといった高度なメモリ管理技術が組み込まれ、膨大なソースコードや本一冊分のテキストを一度に処理できるようになっています。
2. 推論モデル(o1等)と非推論モデル(GPT-4/4.1等)の違い
最近では、内部的に強化学習を用いた「推論特化型モデル(o1など)」も登場しています。GPT-4シリーズが「入力に対して即座に確率的に最適な言葉を紡ぐ」のに対し、推論モデルは内部で「思考の連鎖(Chain of Thought)」を生成し、自問自答を繰り返してから最終的な答えを出力するアーキテクチャを採用しています。
アーキテクチャ理解をAI開発・プロンプトにどう活かすか?
AIの内部構造を知ると、プロンプトの書き方(AIへの指示出し)が変わります。
💡 プロンプト最適化のコツ:MoEの「ルーター」を迷わせない
MoEアーキテクチャでは、最初の「ルーター」にいかに適切な専門家を選ばせるかが精度を左右します。
そのため、プロンプトの冒頭で「あなたは優秀なC#のシニアエンジニアです」や「ステップバイステップで論理的に分析してください」といった明確な役割(ペルソナ)や処理方針を与えることで、AI内部の正しいエキスパートモデルが発火しやすくなり、出力の質が劇的に向上します。
曖昧な指示は、複数のエキスパートの意見が混ざったような焦点のぼやけた回答を引き起こす原因となります。
まとめ:AIの構造を理解して次世代の開発者へ
本記事では、GPT-4シリーズのアーキテクチャと、GPT-3からの進化の歴史について解説しました。
- GPT-3から4への進化:全社員会議(Dense)から、専門家の分業制(MoE)へ。
- モデルの多様化:テキスト処理から真のマルチモーダル(GPT-4o)へ、そして自律型エージェント(GPT-4.1)へと進化。
- 実践への応用:構造を理解し、明確なペルソナを与えることでプロンプトの精度を高める。
AIのアーキテクチャを理解することは、各種AIツールを使いこなすための強力な土台となります。特に、日々のコーディングや開発業務においてAIアシスタントを導入する際、この知識は大いに役立ちます。
▼ 次のアクションにおすすめの記事
モデルの特性を理解したら、次は実際の開発環境でAIを極限まで使い倒してみましょう。エンジニアの生産性を劇的に上げる具体的な活用術については、以下の記事で徹底解説しています。
- 👉 【完全版】GitHub Copilot活用術!導入からAgent Mode/最新モデル使い分けまで徹底解説
- 👉 GitHub Copilot Chat クックブック解説 | エンジニアの生産性を最大化する厳選プロンプトと活用事例
- 👉 【最新研究】AIコーディングツールの設定ファイルは逆効果?論文から読み解く最適な活用例
最新のAI技術を味方につけ、一歩先のエンジニアリングを目指しましょう!


コメント